Vertrauensintervall
Was ist das Vertrauensintervall:
Es ist eine Schätzung eines in der Statistik verwendeten Bereichs, der einen Populationsparameter enthält. Dieser unbekannte Populationsparameter wird durch ein aus den gesammelten Daten berechnetes Mustermodell ermittelt .
Beispiel: Der Durchschnitt einer entnommenen Probe x̅ stimmt möglicherweise nicht mit dem wahren Populationsmittelwert μ überein. Hierzu ist es möglich, eine Auswahl von Stichprobenmitteln zu betrachten, in denen dieser Populationsmittelwert enthalten sein kann. Je länger dieses Intervall ist, desto größer ist die Wahrscheinlichkeit, dass dies auftritt.
Das Konfidenzintervall wird als Prozentsatz ausgedrückt, der sich auf das Konfidenzniveau bezieht, wobei 90%, 95% und 99% am meisten angegeben sind. In der Abbildung unten haben wir beispielsweise ein Vertrauensintervall von 90% zwischen den oberen und unteren Grenzen (a und -a ).
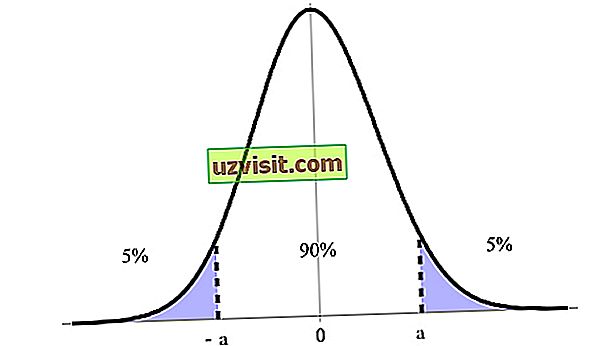
Das Konfidenzintervall ist eines der wichtigsten Konzepte beim Hypothesentest in der Statistik, da es als Maß für die Unsicherheit verwendet wird. Der Begriff wurde 1937 vom polnischen Mathematiker und Statistiker Jerzy Neyman eingeführt .
Welche Relevanz hat ein Vertrauensintervall?
Das Konfidenzintervall ist wichtig, um die Unsicherheitsspanne (oder Ungenauigkeit) gegenüber einer durchgeführten Berechnung anzugeben. Diese Berechnung verwendet die Studienstichprobe, um die tatsächliche Größe des Ergebnisses in der Quellpopulation zu schätzen.
Die Berechnung eines Konfidenzintervalls ist eine Strategie, die die Fehlersuche berücksichtigt. Die Größe des Ergebnisses Ihrer Studie und Ihr Vertrauensintervall kennzeichnen die angenommenen Werte für die ursprüngliche Grundgesamtheit.
Je enger das Konfidenzintervall ist, desto größer ist die Wahrscheinlichkeit, dass der Prozentsatz der Studienpopulation die tatsächliche Anzahl der Quellpopulation darstellt. Dies gibt eine größere Sicherheit hinsichtlich des Ergebnisses des Studienobjekts.
Wie interpretiere ich ein Vertrauensintervall?
Die korrekte Interpretation des Konfidenzintervalls ist wahrscheinlich der schwierigste Aspekt dieses statistischen Konzepts. Ein Beispiel für die gebräuchlichste Interpretation des Konzepts ist folgendes:
Es besteht eine Wahrscheinlichkeit von 95%, dass der wahre Wert des Populationsparameters (z. B. der Durchschnitt) in der Zukunft in den Bereich X (untere Grenze) und Y (obere Grenze) fällt.
Daher wird das Konfidenzintervall wie folgt interpretiert: Es ist zu 95% überzeugt, dass das Intervall zwischen X (Untergrenze) und Y (Obergrenze) den wahren Wert des Populationsparameters enthält.
Es wäre völlig falsch zu sagen: Es besteht eine Wahrscheinlichkeit von 95%, dass das Intervall zwischen X (Untergrenze) und Y (Obergrenze) den tatsächlichen Wert des Populationsparameters enthält.
Die obige Aussage ist das häufigste Missverständnis über das Konfidenzintervall. Nachdem der statistische Bereich berechnet wurde, kann er nur den Populationsparameter enthalten oder nicht.
Die Intervalle können jedoch zwischen den Stichproben variieren, während der tatsächliche Populationsparameter unabhängig von der Stichprobe derselbe ist.
Daher kann die Konfidenzaussage des Konfidenzintervalls nur in dem Fall gemacht werden, in dem die Konfidenzintervalle für die Anzahl der Abtastungen neu berechnet werden.
Die Schritte zur Berechnung des Vertrauensintervalls
Der Bereich wird anhand der folgenden Schritte berechnet:
- Sammeln Sie die Beispieldaten: n ;
- Berechnen Sie den Mittelwert der Probe x̅;
- Bestimmen Sie, ob eine Populationsstandardabweichung ( σ ) bekannt oder unbekannt ist.
- Wenn eine Populationsstandardabweichung bekannt ist, kann ein Z- Punkt für das entsprechende Konfidenzniveau verwendet werden.
- Wenn eine Populationsstandardabweichung unbekannt ist, können wir eine Statistik t für das entsprechende Konfidenzniveau verwenden.
- Daher werden die unteren und oberen Grenzen des Konfidenzintervalls mithilfe der folgenden Formeln ermittelt:
a) Standardabweichung einer bekannten Population :
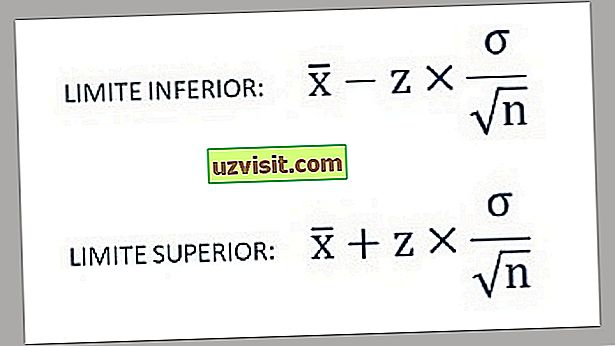
Formel zur Berechnung der Standardabweichung einer bekannten Grundgesamtheit.
b) Standardabweichung einer unbekannten Population :

Formel zur Berechnung der Standardabweichung einer unbekannten Population.
Praktisches Beispiel eines Konfidenzintervalls
In einer klinischen Studie wurde der Zusammenhang zwischen Asthma und dem Risiko einer Obstruktiven Schlafapnoe bei Erwachsenen untersucht.
Einige Erwachsene wurden nach dem Zufallsprinzip aus einer Liste von Staatsbeamten rekrutiert, die vier Jahre lang verfolgt wurden.
Teilnehmer mit Asthma hatten im Vergleich zu denen ohne Asthma ein erhöhtes Risiko, innerhalb von vier Jahren Apnoe zu entwickeln.
Bei der Durchführung klinischer Forschung wie diesem Beispiel wird in der Regel eine Untergruppe der interessierenden Bevölkerung rekrutiert, um die Effizienz der Studien zu erhöhen (weniger Kosten und weniger Zeit).
Diese Untergruppe von Personen, die untersuchte Bevölkerung, setzt sich aus Personen zusammen, die die Einschlusskriterien erfüllen und sich zur Teilnahme an der Studie bereit erklären (siehe Abbildung unten).

Dann wird die Studie abgeschlossen und eine Effektgröße (zum Beispiel eine mittlere Differenz oder ein relatives Risiko ) berechnet, um die Forschungsfrage zu beantworten.
Dieser als Inferenz bezeichnete Prozess beinhaltet die Verwendung von Daten, die aus der Studienpopulation erhoben wurden, um den Umfang der tatsächlichen Auswirkungen auf die interessierende Population, dh die Herkunftspopulation, abzuschätzen.
In dem angeführten Beispiel rekrutierten die Forscher eine Zufallsstichprobe von Staatsangestellten (Quellbevölkerung), die berechtigt waren und an der Studie teilnahmen (Studienbevölkerung), und berichteten, dass Asthma das Risiko der Entwicklung einer Apnoe in der Studienpopulation erhöht.
Um einen Stichprobenfehler aufgrund der Rekrutierung nur einer Untergruppe der interessierenden Population zu berücksichtigen, berechneten sie außerdem ein 95% -Konfidenzintervall (um die Schätzung herum) von 1, 06 bis 1, 82, was eine Wahrscheinlichkeit von 95 anzeigt %, dass das wahre relative Risiko in der Quellbevölkerung zwischen 1, 06 und 1, 82 liegen würde .
Vertrauensintervall für den Durchschnitt
Wenn man Informationen über die Standardabweichung einer Grundgesamtheit hat, kann man ein Vertrauensintervall für den Durchschnitt oder den Durchschnitt dieser Grundgesamtheit berechnen.
Wenn ein gemessenes statistisches Merkmal (wie Einkommen, IQ, Preis, Größe, Menge oder Gewicht) numerisch ist, wird in den meisten Fällen geschätzt, dass der Durchschnittswert für die Grundgesamtheit ermittelt wird.
Daher versuchen wir, den Populationsmittelwert ( μ ) mit einem Stichprobenmittelwert ( x̅ ) mit einer Fehlerquote zu ermitteln. Das Ergebnis dieser Berechnung wird Konfidenzintervall für den Populationsmittelwert genannt .
Wenn die Populationsstandardabweichung bekannt ist, lautet die Formel für ein Konfidenzintervall (CI) für einen Populationsmittelwert:

Wo:
- x̅ ist der Stichprobenmittelwert;
- σ ist die Populationsstandardabweichung;
- n ist die Stichprobengröße;
- Ζ * steht für den entsprechenden Wert der Standardnormalverteilung für Ihr gewünschtes Konfidenzniveau.
Im Folgenden sind die Werte für die verschiedenen Vertrauensstufen ( Ζ * ) aufgeführt:
| Vertrauensstufe | Wert von Z * - |
|---|---|
| 80% | 1, 28 |
| 90% | 1.645 (konventionell) |
| 95% | 1, 96 |
| 98% | 2.33 |
| 99% | 2, 58 |
Die obige Tabelle zeigt z * -Werte für die angegebenen Vertrauensstufen. Beachten Sie, dass diese Werte aus der Standardnormalverteilung (Z-) erhalten werden.
Der Bereich zwischen jedem z * -Wert und dem Negativ dieses Werts ist der (ungefähre) Vertrauensgrad. Zum Beispiel ist der Bereich zwischen z * = 1, 28 und z = -1, 28 ungefähr 0, 80. Daher kann diese Tabelle auch auf andere Vertrauensprozentsätze erweitert werden. Die Tabelle zeigt nur die am häufigsten verwendeten Vertrauensanteile.
Siehe auch die Bedeutung von Hypothese.


